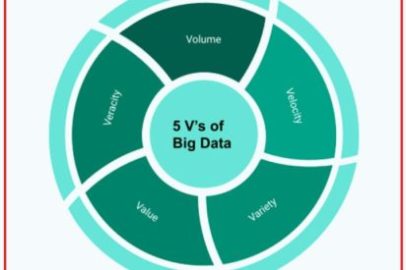
What Are The 5 Vs. Of Big Data?
The first modern manifestation of data analysis probably coincides with Enigma, the machine developed by Turing to decipher the messages used by the Nazis to order military operations. The complexity of the data to be processed required the construction of a computer financed by the British government.
Enigma is not a case in point with the current definition of Big Data. Still, it expresses the context in which the data were analyzed until recently, when Doug Laney, in 2001, theorized the 3V model, effectively opening new horizons. Of the use of data, capable of going well beyond the public functions of defense or management of data relating to the population.
The three Vs. to which Laney refers make up a synthetic model for defining new data, based on a context that sees an exponential increase in information sources:
Volume
Every day the interactions foreseen by human activities (work, study, health, free time, etc.) generate a large amount of data. Volume refers to the mass of information that traditional technologies cannot collect. Although it makes no sense to refer to exclusively quantitative parameters, conventionally, we mean Big Data in two conditions: when the threshold of 50 Terabytes is exceeded or when there is an annual increase in data volume of more than 50% compared to the last year. To offer an order of magnitude of the phenomenon, from 2010 to 2020, the importance of data has increased by about 40 times globally, and the forecasts for 2030 are of exponential growth.
Speed
The proliferation of IoT systems, equipped with special sensors, makes it possible to acquire and process the data directly in the place where it is generated. Therefore, the enormous volume of data referred to in the previous point is a continuous flow of information available in real-time or in the condition of “near real-time.” This speed must also be guaranteed by the applications that analyze the data to assist in real-time with the operations that follow and the decisions to be made in a given context.
Variety
The variety of the data corresponds to a variety of information sources, in a relationship of dependence that grows hand in hand in a heterogeneous direction. In addition to traditional and company management systems, today, sources such as IoT sensors, social networks, and open data are increasingly active and capable of guaranteeing vast flows of structured and unstructured data. From a business point of view, the data can be generated internally or acquired externally. To these original 3Vs, based on the model proposed by Doug Laney, two other Vs. were soon added, the relevance of which is mainly due to how the information value constituted by data is used in the company.
Variability
We are talking about a different concept than the variety above and refers to the matter itself of the data, available in other formats. Consequently, concepts such as interoperability come into play, capable of making the data accessible to various analysis applications, such as those used by the different company lines of business (LoB).
Truthfulness
Those involved in machine learning know very well how critical data selection is. A “bad” data can lead the automatic learning system to produce completely misleading predictive outcomes, making an effort useless and counterproductive. In other words, if the data is not sincere towards what happens in its reference scenario, it is impossible that it can generate a credible forecast value in the simulations carried out. In the case of Big Data, this simple concept is raised to the nth degree.
Taking a cue from the clarifications provided by the Observatories of the Politecnico di Milano, which carry out a timely action of research and monitoring of the 4.0 trends relating to the Italian market, we can add a sixth V, which summarizes the previous ones in the context of value. In literature, especially about marketing texts, it can sometimes happen that we encounter value instead of truthfulness, even if, in our opinion, it is a rather improper classification, especially from an application point of view.
Value (Data, Information, Knowledge)
If the data becomes a source of inestimable value, collecting data is not equivalent to the actual availability of information and does not allow for the automatic generation of knowledge. Data, information, and knowledge are terms in obvious relation to each other, but their affinity is not enough to enhance their differences.
Along an actual or presumed value chain, the data represent an entity, phenomenon, or transition rather than an event. The information derives from a process, even a simple one, of data analysis, with various levels of meaning, which make it accessible only to those who generated it, rather than to an undifferentiated public. Knowledge ultimately derives from using the information to make decisions and carry out actions.
The distinction between data, information, and knowledge explains the need to use Analytics tools to translate the raw value of the raw data into a refined and valuable value to support the achievement of specific objectives, even in very different business areas. They. Before entering into the merits of Big Data Analytics methodologies, let’s conclude the broad premise with the definition of the two main types of data, which correspond to the raw material from which the whole process starts: structured data and unstructured data.
Also Read: What Are Big Data: Concrete Examples Of Everyday Life